A library book yak shave

It is a truth universally acknowledged that a child in a library will find approximately a million books they want to bring home on every visit. With two children, this produces approximately two million books per library visit, and that doesn't include the grownups' random findings on the 'new books' shelf. (I am a sucker for a good-looking cover, and it has seldom led me astray).
So, there are two million library books loose in my house (they're supposed to be in the library books bin, but they inevitably migrate to bedrooms and couches and other such reading nooks), sometimes attempting to become domesticated by sneaking onto our non-library-book shelves. Returning our books is a to do.
The problem
Now, recently, our library updated their catalogue software and it's vastly easier to see which books I have checked out now, which is great! The new view even includes the cover art, which is super helpful when it comes to the actual locating of the lost books. Unfortunately, I suspect they're using some sort of iFrame situation because the beautiful list of books doesn't print. I had two million (17) books checked out, and only 3 showed up when printing.
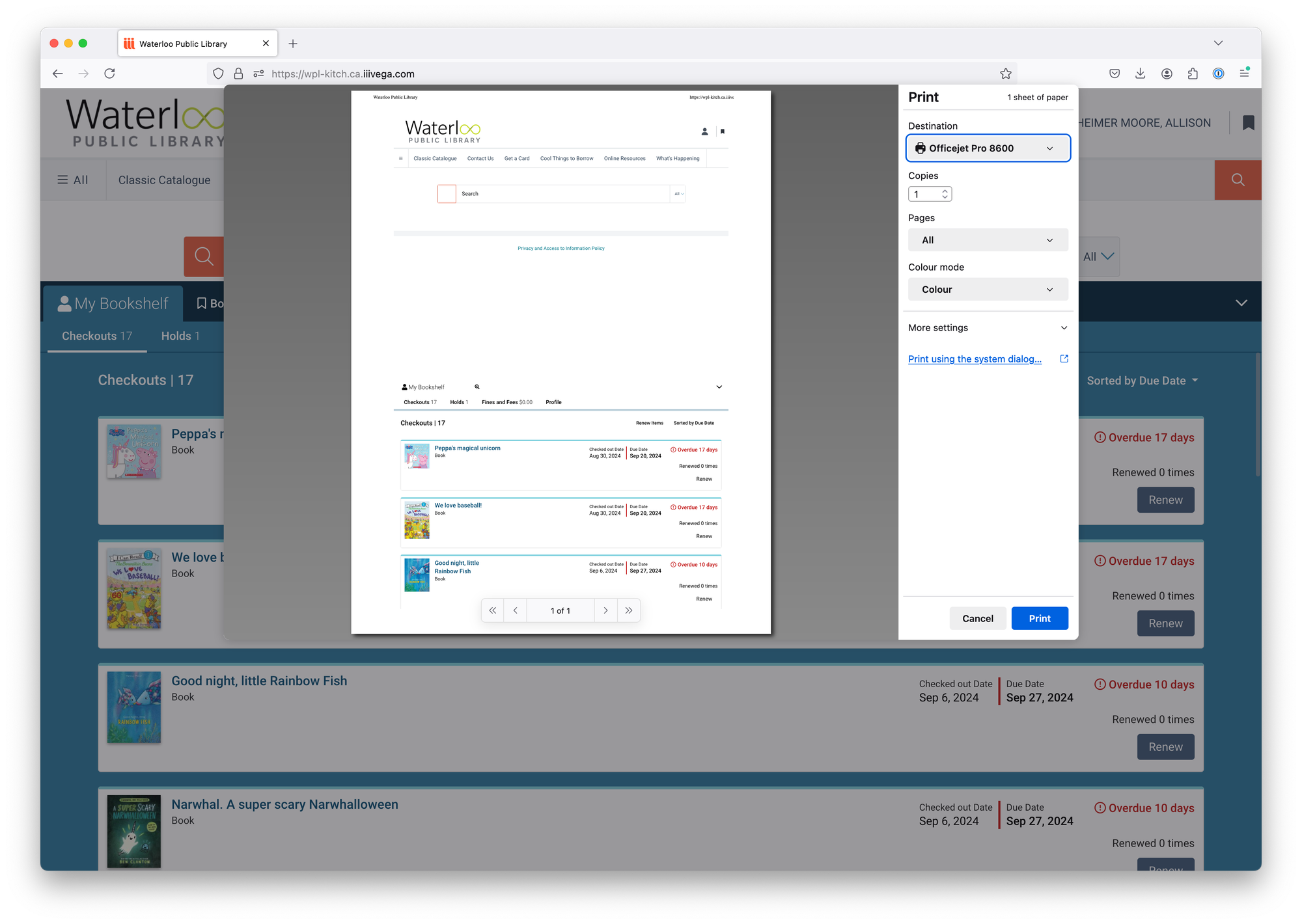
How was I going to send my children around the house on a book hunt without being able to print the list? This is not a format that copy-pastes into a Google Doc well, and I don't want to copy-paste two million book titles. This was rapidly becoming a good old fashioned Yak Shave
Enter… developer tools and a HIGHLY rudimentary python script.
Getting the Data
Obviously, there's some sort of API call that's populating the page - I just needed to find the response object the page was using to build its frustratingly hard-to-print table and then massage that data into a functional format. Looking at developer tools, there was a conveniently named 'checkouts' file being GETed.
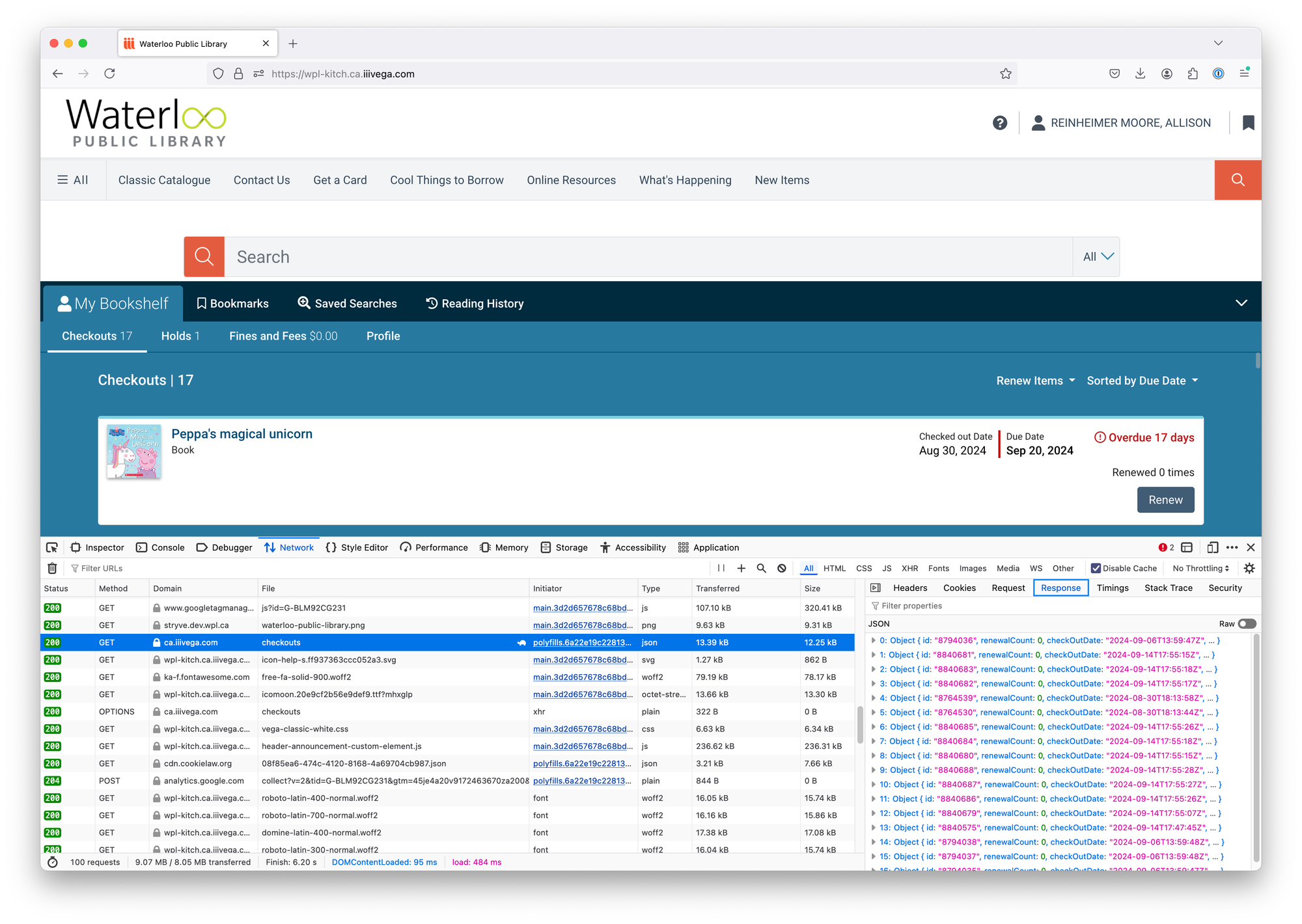
Expanding the objects in the response body, it was clearly the data about the books I had checked out. Huzzah!
Massaging the Data
I like Python so I used Python. I pasted the raw JSON from the checkouts GET response into my IDE, updated all the falses to Falses because Python, and got down to business.
# Steal from https://ca.iiivega.com/api/search-result/patrons/me/checkouts response,
# replace false with False in IDE for formatting purposes.
# Note: I truncated this to have only one book in the list, because readability
books = [{"id":"8794036","renewalCount":0,"checkOutDate":"2024-09-06T13:59:47Z","dueDate":"2024-09-27T08:00:00Z","vendor":"gates","resource":{"id":"b1020873-0ed5-51ba-8d25-4be2b50bd1e8","instanceId":"bcd54875-c486-11ee-8b95-8974cb683634","type":"FormatGroup","title":"Narwhal. A super scary Narwhalloween","materialType":"Book","materialTypeTranslationKey":"format-group.BOOK","coverUrl":{"small":"https://secure.syndetics.com/index.aspx?isbn=9780735266742/sc.gif&upc=&client=kitchvega&type=unbound","medium":"https://secure.syndetics.com/index.aspx?isbn=9780735266742/mc.gif&upc=&client=kitchvega&type=unbound","large":"https://secure.syndetics.com/index.aspx?isbn=9780735266742/lc.gif&upc=&client=kitchvega&type=unbound"},"ill":False}}]
titles = []
for book in books:
titles.append({"title": book["resource"]["title"],
"img": book["resource"]["coverUrl"]["small"]})
out = open("books.html", "w")
out.write("<html><body><table>")
for title in titles:
out.write(f"<tr><td>{title["title"]}</td>")
out.write(f"<td><img src='{title["img"]}'></td></tr>")
out.write("</table></body></html>")Is it the best code I've ever written? Good lord, no. Is it good code? Meh. Does it produce a printable page that I can then hand to my five year-old so she can check if we have all the books we're supposed to have and go searching for the inevitably missing Peppa Pig title? YES!
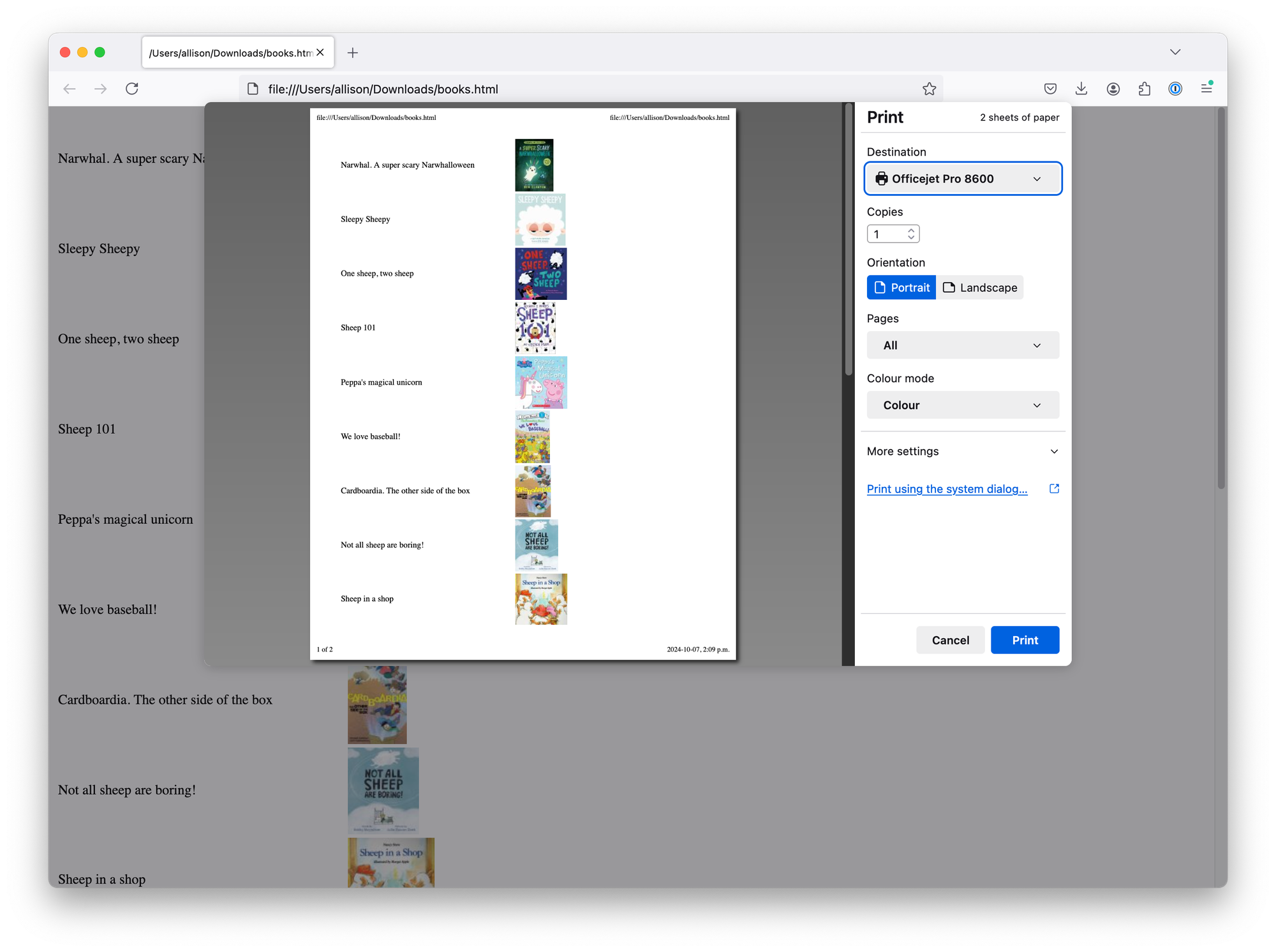
Finding the Books
16/17 books were, in fact, in the book bin (⭐ for the kiddos), and we searched at length for the 17th, only to discover that "Peppa's magical unicorn" had fallen under the bench the book bin was on. The books are checked off, and are ready to head back to the library, perchance to pick out a million more.
So What?!
I'd love for the service our library uses to add a print view of the library book list, but I also realize that libraries aren't flush with cash and that changing software can be hard. This is a slightly ridiculous but reusable solution that I can now rely on for years(?) to come and that will greatly reduce the frustration I feel when I need to figure out which book is the one that's missing, and the guilt I feel when my library books are late. Sometimes a dodgy little script is exactly the right tool for the job.
Notes:
- Yes, all of these books were wildly overdue. Shout out to the Waterloo Public Library for doing away with late fees!
- Yes, I own a printer. When you run four businesses out of your house, there's a surprising amount of printing and scanning, and I'd say I print stuff like 3 times a week between library books, recipes, and random school stuff.
- I wanted to automate the pulling of the data a little bit, but they've got some CORS stuff set up to block that (well done, library vendor!) so no dice. I'll be copy-pasteing the raw response for the time being.